|
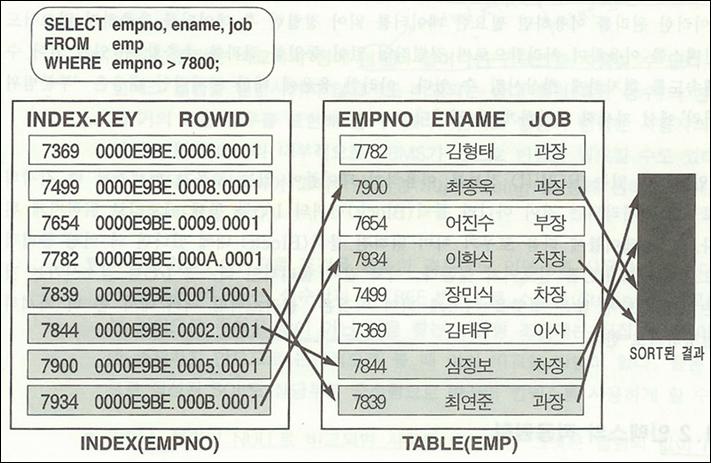
<лҢҖмҡ©лҹүлҚ°мқҙн„°лІ мқҙмҠӨ мҶ”лЈЁм…ҳ1 5page к·ёлҰјм°ёкі >
- B*Tree л°©мӢқмңјлЎң мЎ°кұҙмқ„ л§ҢмЎұн•ҳлҠ” мІ« лІҲм§ё мқёлҚұмҠӨ ROWлҘј м°ҫлҠ”лӢӨ.
- мЎ°кұҙм—җ н•ҙлӢ№н•ҳлҠ” мІҳлҰ¬к°Җ лҒқлӮ л•Ң к№Ңм§Җ м°ЁлЎҖлҢҖлЎң лӢӨмқҢ ROWлҘј мҠӨмә” н•ңлӢӨ.
- мқёлҚұмҠӨ ROWм—җ мһҲлҠ” ROWID м •ліҙлҘј мқҙмҡ©н•ҳм—¬ н…Ңмқҙлё”м—җ мһҲлҠ” мӢӨм ң ROWлҘј лһңлҚӨн•ҳкІҢ м•Ўм„ёмҠӨ н•ңлӢӨ.
- кІ°көӯ м•Ўм„ёмҠӨлҗҳлҠ” н…Ңмқҙлё” ROWмқҳ мҲңм„ңлҠ” мқёлҚұмҠӨ ROWмқҳ мҲңм„ңмҷҖ мқјм№ҳн•ңлӢӨ.
- к·ёлҹ¬лҜҖлЎң мқёлҚұмҠӨлҘј мқҙмҡ©н•ҳм—¬ мІҳлҰ¬н•ЁмңјлЎңмҚЁ м •л ¬мһ‘м—… м—Ҷмқҙ лҸҷмқјн•ң кІ°кіјлҘј 추м¶ңн• мҲҳ мһҲлӢӨ.
1.2 мқёлҚұмҠӨмқҳ м Ғмҡ©мӣҗм№ҷ
 |
мқёлҚұмҠӨк°Җ мӮ¬мҡ©лҗҳм§Җ м•ҠлҠ” кІҪмҡ°
- мқёлҚұмҠӨ컬лҹјмқҳ ліҖнҳ•(Suppressing)
- л¶Җм •нҳ•л№„көҗ
- NULLмқ„ мӮ¬мҡ©н•ң 비көҗ
- мҳөнӢ°л§Ҳмқҙм ём—җ мқҳн•ң м·ЁмӮ¬м„ нғқ
|
к°Җ. мқёлҚұмҠӨ컬лҹјмқҳ ліҖнҳ•(Suppressing)
(1) мҷёл¶Җм Ғ(External) ліҖнҳ•
SELECT dept, ename
FROM emp
WHERE SUBSTR(job, 1, 4)='SALE' |
SELECT dept, ename
FROM emp
WHERE job LIKE 'SALE%' |
SELECT dept, ename
FROM emp
WHERE sal*12 = 100000 |
SELECT dept, ename
FROM emp
WHERE sal = 100000/12 |
SELECT dept, ename
FROM emp
WHERE NVL(job, 'X') = 'SALE' |
SELECT dept, ename
FROM emp
WHERE job = 'SALE' |
- мқёлҚұмҠӨмқҳ нҠ№м§•мқ„ м—ӯмңјлЎң мқҙмҡ©н•ҳм—¬ мҲҳн–үмҶҚлҸ„лҘј н–ҘмғҒ.
=> 'CUSTNO'мҷҖ 'STATUS'лҠ” к°Ғк°Ғ мқёлҚұмҠӨк°Җ мғқм„ұлҗҳм–ҙ мһҲкі 'STATUS'к°Җ '90'мқё кІҪмҡ°м—җлҠ” 분нҸ¬лҸ„к°Җ л„“лӢӨкі к°Җм •н•ҳл©ҙ..
SELECT custno, chuldate
FROM chulgot
WHERE custno = 'DN01'
AND status = '90' |
SELECT custno, chuldate
FROM chulgot
WHERE custno = 'DN01'
AND RTRIM(status) = '90' |
=> ORD_DATE LIKE '9502%'лҘј л§ҢмЎұн•ҳлҠ” лЎңмҡ°мҲҳк°Җ ORD_DEPT = '12345'лҘј л§ҢмЎұн•ҳлҠ” лЎңмҡ° мҲҳліҙлӢӨ м ҒлӢӨкі к°Җм • н–Ҳмқ„ кІҪмҡ°..
SELECT x.ordno, x.ord_date, y.item, y.ordqty
FROM ORDER1T x, ORDER2T y
WHERE x.ordno = y.ordno
AND x.ord_date LIKE '9502%'
AND y.orddept = '12345'
ORDER BY ord_date |
SELECT x.ordno, x.ord_date, y.item, y.ordqty
FROM ORDER1T x, ORDER2T y
WHERE x.ordno = y.ordno
AND x.ord_date LIKE '9502%'
AND RTRIM(y.orddept = '12345')
ORDER BY ord_date |
=> sale_dept к°Җ 95л…„лҸ„мқё лҚ°мқҙн„°к°Җ м•„мЈј л§Һкі , sale_deptлЎң мғқм„ұлҗң мқёлҚұмҠӨк°Җ мһҲлӢӨкі к°Җм • н–Ҳмқ„ кІҪмҡ°..
SELECT sal_no, sale_date, sale_dept, saleqty
FROM mechult
WHERE sale_date LIKE '95%'
ORDER BY sale_dept |
SELECT sal_no, sale_date, sale_dept, saleqty
FROM mechult
WHERE RTRIM(sale_date) LIKE '95%'
AND sale_dept > '' |
(2) лӮҙл¶Җм Ғ ліҖнҳ•
лӮҳ. л¶Җм •нҳ•л№„көҗ
- л¶Җм •нҳ•мқ„ кёҚм •нҳ•мңјлЎң мң лҸ„
SELECT 'Not found'
FROM EMP
WHERE EMPNO <> 7369 |
SELECT 'NOT FOUND'
FROM DUAL
WHERE NOT EXISTS
( SELECT 'X' FROM EMP
WHERE EMPNO = 7369 ) |
SELECT 'Not found'
FROM emp a
WHERE NOT EXISTS
(SELECT empno FROM emp b
WHERE b.empno = 7369
AND a.empno = b.empno) |
=> TAB1н…Ңмқҙлё”мқҳ 'YYYYMM','COL1'к°Җ к°Ғк°Ғ мқёлҚұмҠӨлЎң мғқм„ұлҗҳм–ҙ мһҲкі TAB2мқҳ 'YYYYMM','COL2'к°Җ к°Ғк°Ғ мқёлҚұмҠӨлЎң мғқм„ұлҗҳм–ҙ мһҲлӢӨ
1)
SELECT *
FROM TAB1
WHERE YYYYMM = '199910'
FROM TAB2AND NOT EXISTS ( SELECT *
WHERE COL2 = COL1
AND YYYYMM = '199910') |
2)
SELECT *
FROM TAB1
WHERE YYYYMM ='199910'
AND COL1 NOT IN (SELECT COL2
FROM TAB2
WHERE YYYYMM = '199910') |
3)
SELECT *
FROM TAB1
WHERE (YYYYMM, COL1) IN (SELECT '199910', COL1
FROM TAB1
WHERE YYYYMM = '199910'
MINUS
SELECT '199910', COL2
FROM TAB2
WHERE YYYYMM = '199910') |
1) кіј 2) м—җм„ңмқҳ subмҝјлҰ¬лҠ” лӮҳмӨ‘м—җ мҲҳн–үлҗҳкұ°лӮҳ checkмЎ°кұҙмңјлЎң мҲҳн–үлҗңлӢӨ.
3) мқё кІҪмҡ°м—” м„ңлёҢмҝјлҰ¬м—җм„ң MINUSкІ°кіјлҘј лЁјм Җ мҲҳн–үн•ҳкі , к·ё кІ°кіјлҘј к°Җм§Җкі л©”мқёмҝјлҰ¬лҘј м—‘м„ёмҠӨ н•ңлӢӨ.
к°Ғк°Ғ н…Ңмқҙлё”м—җ 'YYYYMM+COL1','YYYYMM+COL2'лЎң кө¬м„ұлҗң мқёлҚұмҠӨк°Җ мһҲлӢӨл©ҙ н…Ңмқҙлё”мқ„ м—‘м„ёмҠӨ н•ҳм§Җ м•Ҡкі мқёлҚұмҠӨл§Ң к°Җм§Җкі sort mergeл°©мӢқмңјлЎң м„ңлёҢмҝјлҰ¬лҘј лЁјм Җ мҲҳн–үн•ң нӣ„ мІҳлҰ¬лҗң м„ңлёҢмҝјлҰ¬мқҳ кІ°кіјлЎң л©”мқёмҝјлҰ¬мқҳ мЎ°кұҙмңјлЎң мӮ¬мҡ©н•ңлӢӨ.
лӢӨ. NULLмқ„ мӮ¬мҡ©н•ң 비көҗ
(1) NULL컬лҹјмқҳ м Ғмҡ©
SELECT *
FROM emp
WHERE ename IS NOT NULL |
SELECT *
FROM emp
WHERE ename > '' |
SELECT *
FROM emp
WHERE empno IS NOT NULL |
SELECT *
FROM emp
WHERE empno > 0 |
- мҳөнӢ°л§Ҳмқҙм ё лӘЁл“ңк°Җ Rule_based мқҙкұ°лӮҳ Cost_based лӘЁл“ңм—җм„ң 'FIRST_ROWS'лЎң м„Өм •лҗҳм—Ҳмқ„ л•Ң к°ҖлҠҘн•ҳлӢӨ.
- SUM, COUNT, MAX, MIN, AVGл“ұмқҳ к·ёлЈ№н•ЁмҲҳлҘј мӮ¬мҡ©н–Ҳкұ°лӮҳ, GROUP BY, ORDER BY, UNION, MINUS, INTERSECTл“ұмқ„ мӮ¬мҡ©н•ҳл©ҙ м „мІҙлІ”мң„лҘј мқёлҚұмҠӨлҘј кІҪмң н•ЁмңјлЎң мқёлҚұмҠӨлҘј мӮ¬мҡ©н•ҳлҠ” кІғмқҙ нӣЁм”¬ л¶ҲлҰ¬н•ҳлӢӨ.
SELECT *
FROM emp
WHERE ename IS NULL |
CREATE TABLE emp(
ename VARCHAR2(20) DEFAULT '00'
......
) |
- 분нҸ¬лҸ„к°Җ м–‘нҳён• кІҪмҡ°м—җлҠ” Default мӮ¬мҡ©мқҙ мң лҰ¬, к·ёл Үм§Җ м•Ҡмқ„ кІҪмҡ°м—җлҠ” null к°’мқ„ к°Җм§Җкі мһҲлҠ” кІғмқҙ мң лҰ¬н•ҳлӢӨ.
(2) NULLкіөнҸ¬мҰқмқҳ н•ҙмҶҢ
- NULLлҸ„ 1, AмҷҖ к°ҷмқҖ н•ҳлӮҳмқҳ к°’мқҙлӢӨ.
- м–ҙл–Ө к°’ліҙлӢӨ нҒ¬м§ҖлҸ„ м•Ҡкі мһ‘м§ҖлҸ„ м•ҠлӢӨ.'
- к·ёлҹ¬лҜҖлЎң м–ҙл–Ө к°’кіј 비көҗ лҗ мҲҳлҸ„ м—ҶлӢӨ.
- мҰү NULLкіј м—°мӮ° кІ°кіјлҠ” NULLмқҙ лҗңлӢӨ.
SELECT ord_dept, SUM(ordqty), AVG(ordqty+asnqty), AVG(ordqty)
FROM ORDER
WHERE status < 'C'
GROUP BY ord_dept
- statusк°Җ nullмқё к°’мқҖ мһ‘м—…лҢҖмғҒм—җм„ң л№ м§„лӢӨ.
- AVG(ordqty+asnqty)лҠ” ordqtyлӮҳ asnqty мӨ‘ н•ҳлӮҳл§Ң NULLмқ„ к°Җ진лӢӨл©ҙ мІҳлҰ¬лҢҖмғҒм—җм„ң м ңмҷёлҗңлӢӨ.
- SUM(ordqty) мҷҖ SUM(nvl(ordqty,0)) мқҖ лҸҷмқјн•ҳлӢӨ.(кІ°кіјлҠ” лҸҷмқјн•ҳлӮҳ нӣ„мһҗлҠ” л¶Ҳн•„мҡ”н•ң м—°мӮ°мқ„ мҲҳн–үн•ҳлҜҖлЎң л¶ҲлҰ¬н•Ё)
- AVG(ordqty+asnqty) мҷҖ AVG(nvl(ordqty,0)+nvl(asnqty,0))лҠ” м„ңлЎң лӢӨлҘҙлӢӨ.
- AVG(ordqty) м—җм„ң ordqtyм—җ NULLмқҙ мһҲмқ„л•ҢмҷҖ м—Ҷмқ„л•Ңмқҳ м°Ёмқҙм җ??
|
NULL кіөнҸ¬мҰқмқҳ н•ҙмҶҢ л°©м•Ҳ
'нҷ•м •мқҖ лҗҳм—ҲмңјлӮҳ к°’мқҙ м—ҶлӢӨ' кІҪмҡ°м—җлҠ” л¬ёмһҗ нғҖмһ…мқј л•ҢлҠ” ' '(Space)лӮҳ кё°нғҖ л¬ёмһҗлҘј н•„мҡ”м—җ л”°лқј м§Җм •н•ҳкі , мҲ«мһҗ нғҖмһ…мқј л•ҢлҠ” 0 мқ„ м§Җм •н•ңлӢӨ.
'лҜёнҷ•м •'мқё к°’лҸ„ н•ҳлӮҳмқҳ мқҳлҜёлҘј м§ҖлӢҢ к°’мқҙлқјкі ліҙм•„м•ј н•ңлӢӨлҠ” кІғмқҙ NULL к°’мқҙ л§Ңл“Өм–ҙ진 мқҙмң мқҙлӢӨ.
н…Ңмқҙлё”мқ„ мғқм„ұмӢң DEFAULT м ңм•ҪмЎ°кұҙмқ„ мқҙмҡ©н•ҙм„ң кё°ліёк°’мқ„ м§Җм •н•ҳм—¬ мІҳлҰ¬ н• мҲҳлҸ„ мһҲлӢӨ.
NVLн•ЁмҲҳмқҳ мӮ¬мҡ©мңјлЎң мқён•ң л¶Ҳн•„мҡ”н•ң м—°мӮ° ліҙлӢӨлҠ” NULLк°’м—җ лҢҖн•ң мқјкҙҖм„ұмқ„ мң м§Җн•ҳлҠ” кІғмқҙ н•„мҡ”н•ҳлӢӨ. |
лқј. мҳөнӢ°л§Ҳмқҙм ём—җ мқҳн•ң м·ЁмӮ¬м„ нғқ
(1) мҲңмң„(Ranking)мқҳ м°Ёмқҙ
SELECT ord_dept, ordqty
FROM ORDER1T
WHERE status = 'C'
AND ord_date like '9502%'
- RBO: мҲңмң„м—җ мқҳн•ҙм„ң ord_date мқёлҚұмҠӨлҠ” л¬ҙмӢңлҗҳкі , statusмқёлҚұмҠӨлҘј мӮ¬мҡ©.
- CBO: 분нҸ¬лҸ„м—җ л”°лқј мҳөнӢ°л§Ҳмқҙм Җк°Җ м„ нғқ.
SELECT ord_dept, ordqty
FROM ORDER1T
WHERE status = 'C'
AND ord_date = '950201'
- к°Ғ 컬лҹјмқҙ лі„к°ңмқҳ мқёлҚұмҠӨлЎң мғқм„ұмқҙ лҗҳм–ҙ мһҲлӢӨл©ҙ мқёлҚұмҠӨ лЁём§ҖлҘј мқјмңјнӮҙ
SELECT ord_dept, ordqty
FROM ORDER1T
WHERE ord_dept like '12%'
AND ord_date like '9502%'
- л‘җк°ң мқёлҚұмҠӨмӨ‘ н•ҳлӮҳл§Ң мӮ¬мҡ©н•Ё.
- RBO: лӮҳмӨ‘м—җ мғқм„ұлҗң 컬лҹј мӮ¬мҡ©.
- CBO: 분нҸ¬лҸ„м—җ л”°лқј мҳөнӢ°л§Ҳмқҙм Җк°Җ м„ нғқ.
|
лІ”мң„ мІҳлҰ¬к°Җ л„“лӢӨкі н• мҲҳ мһҲлҠ” 'LIKE', 'BETWEEN', '<', '>'л“ұкіј к°ҷмқҙ мӮ¬мҡ©лҗ кІҪмҡ° кІ°мҪ” мқёлҚұмҠӨ лЁём§ҖлҘј н•ҳм§Җ м•Ҡкі м–ҙлҠҗ н•ҳлӮҳмқҳ мқёлҚұмҠӨл§Ң мӮ¬мҡ©н•ҳкі лӮҳлЁём§ҖлҠ” нҸ¬кё°н•ңлӢӨ. |
(2) лӮ®мқҖ мІҳлҰ¬л№„мҡ©мқҳ м„ нғқ
SELECT *
FROM emp
WHERE ename > 'A'
- FIRST_ROWS лЎң м„Өм •лҗҳм—Ҳмқ„ л•Ң мқёлҚұмҠӨлҘј мӮ¬мҡ©н•ҳм§Җл§Ң ALL_ROWSмқё кІҪмҡ°м—җлҠ” м „мІҙ н…Ңмқҙлё”мқ„ мҠӨмә” н•Ё.
(3) нһҢнҠё(Hint)м—җ мқҳн•ң м„ нғқ
- мҳөнӢ°л§Ҳмқҙм ёк°Җ м•Ўм„ёмҠӨ кІҪлЎңлҘј кІ°м •н• л•Ң мҳөнӢ°л§Ҳмқҙм ём—җкІҢ лӘЁл“ кІғмқ„ л§Ўкё°м§Җ м•Ҡкі мӮ¬мҡ©мһҗк°Җ мӣҗн•ҳлҠ” ліҙлӢӨ мўӢмқҖ м ‘к·јкІҪлЎңлҘј м§Ғм ‘ м„ нғқн•ҙм„ң мөңм Ғмқҳ нҠңлӢқмқ„ н• мҲҳ мһҲлҸ„лЎқ лҸ„мҷҖмӨҢ
|
нһҢнҠёмқҳ мӮ¬мҡ© л°©лІ•
/*+ */ : нһҢнҠёмқҳ лӮҙмҡ©мқ„ м—¬лҹ¬ лқјмқём—җ кұёміҗм„ң кё°мҲ н• мҲҳ мһҲмқҢ.
--+ : мҳӨм§Ғ н•ң лқјмқём—җл§Ң кё°мҲ н•ҙм•ј н•ҳл©°, 컬лҹјмқҖ л°ҳл“ңмӢң лӢӨмқҢ лқјмқём—җ кё°мҲ н•ҙм•ј н•Ё. |
|